


Scrolling No More: Building my own movie recommendation model that actually works (Hopefully..)
A non-Econ article

We have all been there, it is the weekend with your favorite snacks ready, while scrolling endlessly through Netflix only to waste two precious hours on a movie that leaves you wondering, “Who actually likes this stuff!” Or maybe a close friend with good intentions swears that you must watch their latest favorite movie, only to realize that you have wasted 2-3 hours of your weekend after watching it.
After losing countless evenings to mediocre suggestions from both Netflix’s algorithms and friends, I figured enough was enough. I further recalled that since 2010, I have been rating movies on IMDb, with approximately 523 movies reviewed until now. I essentially had a goldmine of personal preference data sitting unutilized. If friends and Netflix could not figure out what I actually enjoy watching, perhaps it is time to experiment with a system that could do a better job?
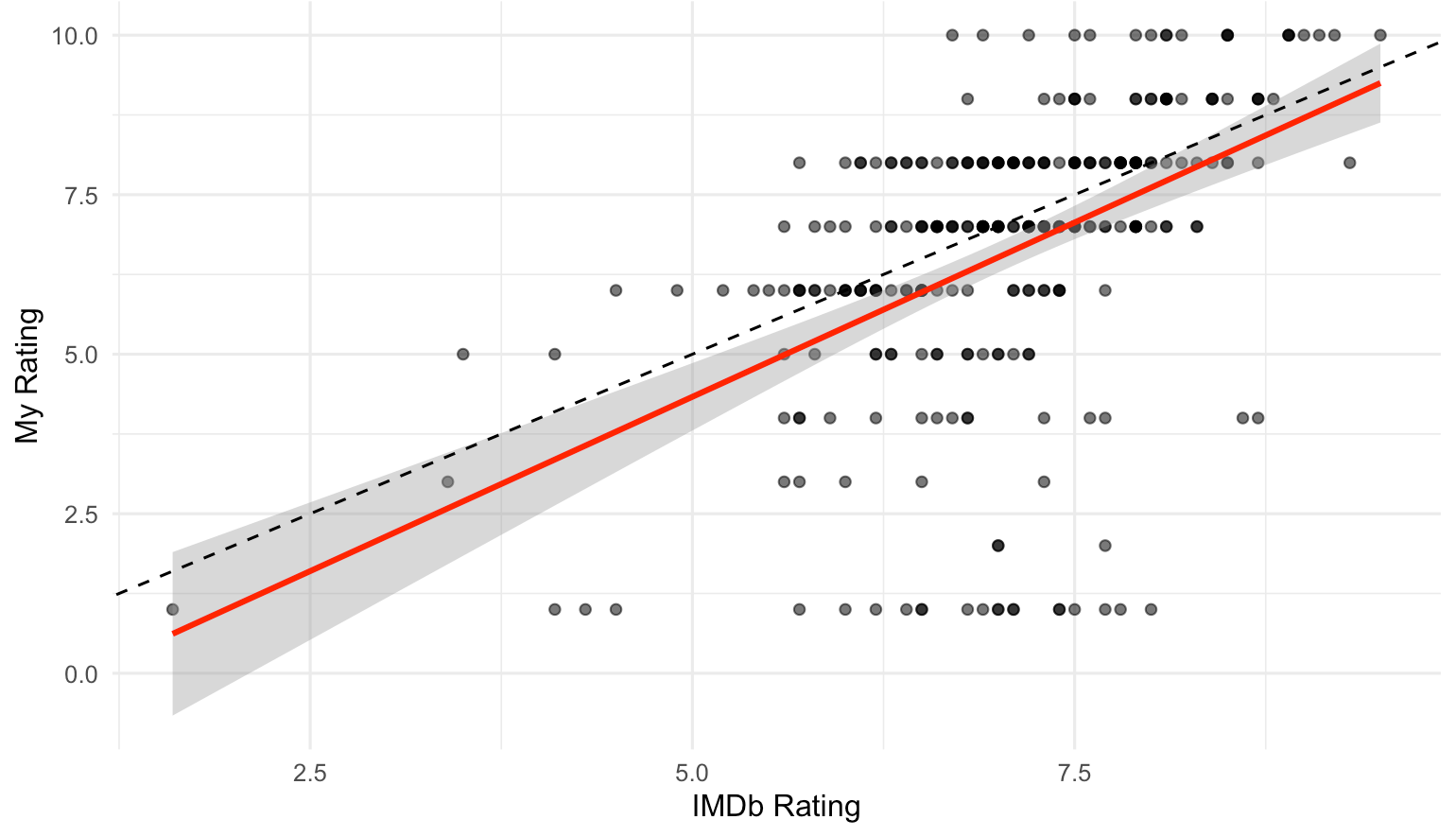
First, I wanted to see how my taste compares to the average IMDb user. Turns out, I am slightly tougher to please. My average rating sits at roughly 6.56 out of 10, compared to IMDb’s 7.04. Looking at the graph comparing my ratings to IMDb’s, the trend red line falls consistently below the diagonal, which indicates that in general I tend to rate movies lower than the average IMDB users.
Figure 1. My rating vs. IMDb’s average user rating
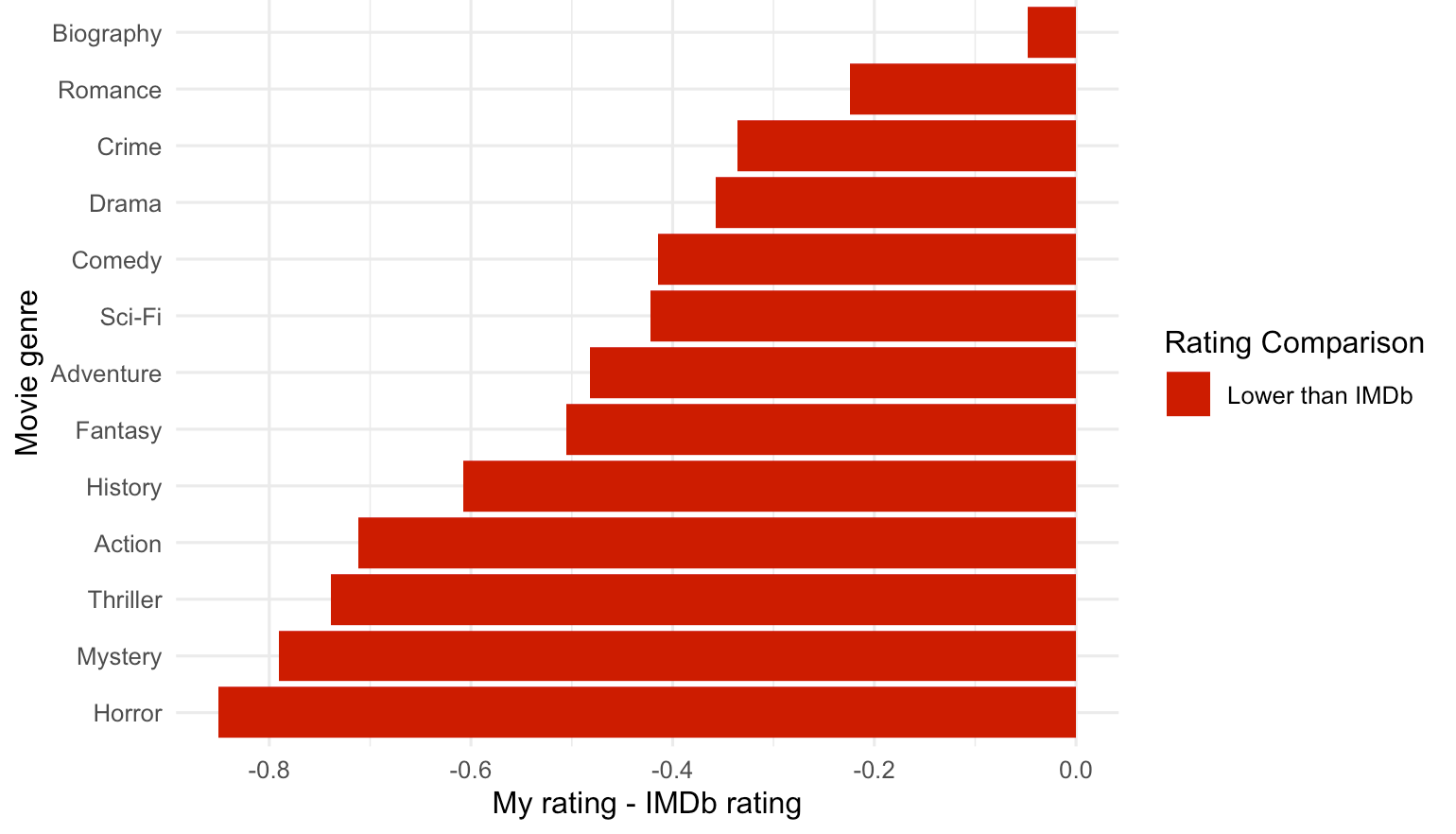
One fascinating insight came from breaking down ratings by each movie’s genre (i.e. horror, drama, etc..). Specifically, it seems that I consistently rate some genres such as Horror and Mystery significantly lower than the IMDb’s average rating, I tend to rate Biography and Crime movies somewhat similar to the site’s other users. For Horror movies, on average I rated them lower by 0.90 points than the average IMDb rating.
Figure 2. My rating vs. IMDb rating by movie genre/type
The Decade Divide
I also discovered my sweet spots by decade: My ratings graph shows something I have always suspected, but could never prove: my movie taste are unfortunately stuck in a time warp! Although the average IMDb user (i.e. the steady red line) finds something to love across all decades, my enjoyment takes a nosedive starting around 2000’s. The 1980s and 90s films consistently hit my sweet spot. I now genuinely think my recommendation algorithm isn’t just a tech project; but rather it is my personal time machine to find modern films with that classic feel my brain is more likely to appreciate.
Figure 3. My average ratings by movie decade

To take this even further, I created a simple recommendation algorithm. The code looks for movies I have not watched yet from a list of 150 top horror, sci-fi, and drama films. I then computed the similarity scores between these unwatched movies and everything that I have watched and given an 8+ rating. Here are some of the top recommendations that the model generated.
What’s interesting in the graph below is that my system identified connections I would not have made myself. Despite my general indifference toward comedies, “Zombieland” topped the list because it shares specific qualities with “The Hangover,” one of the few comedy movies I actually enjoyed
Figure 4. My top movie recommendations by Similarity Scores

Now was all this coding worth the effort or did I just waste roughly 7 hours of my weekend writing this code and article? Perhaps, but considering those hours could have been spent watching more below average films that some algorithm incorrectly thought I would enjoy, I think I will call this a win. My personalized movie matchmaker now seems to understand my inexplicable breakup with post-2000 cinema. Now I can decline friends’ movie suggestions with scientific, albeit obnoxious authority: “Sorry, but your recommendation only scored 0.42 on my compatibility index, so I am not watching it.” Of course, it is also plausible that I have just created an elaborate excuse for rewatching 80s-90’s classics (i.e. Back to the Future), but I am watching better movies now, and that’s worth every code chunk.